All examples provided in a Github Gist at the end of this article.
What is DynamoDB?
Overview
Amazon DynamoDB is a database service built to perform well at scale. Since it is a managed service, you don’t have to worry about managing and scaling a database server. There are caveats that I’ll go over later in this post.
Key Points and Differences from Other Databases
Here are some important considerations when thinking about using DynamoDB for your database:
- DynamoDB uses tables similar to MySQL, but they are non-relational meaning that you cannot write SQL joins.
- DynamoDB is semi-schemaless, like MongoDB, in that you can insert objects into the database without defining the fields ahead of time. (semi-schemaless because you must provide a name for the primary key)
- Unlike MySQL, the “Primary Key” does not have to be unique. Instead, a composite key is used for a unique key.
Why would I want to use DynamoDB?
Scalability and performance are the main reasons to use DynamoDB. Since there is no server to manage, you save time on DevOps.
You don’t have to build the architecture for a scalable database, but you need to change the way to get data in and out of the database. Plus you need to change the way you design the tables. That said, there is a learning curve to using DynamoDB.
I’ll cover database design considerations, then show examples of interacting with DynamoDB using Boto3 next.
How to design a DynamoDB table?
Designing a DynamoDB table is much different than designing a MySQL table. The main reason is that you cannot predefine your entire table like you would with MySQL. When you create a DynamoDB table, you only have the options to define a primary key and a sort key. The table definition determines how your data can be queried.
Basics of Primary and Sort Keys
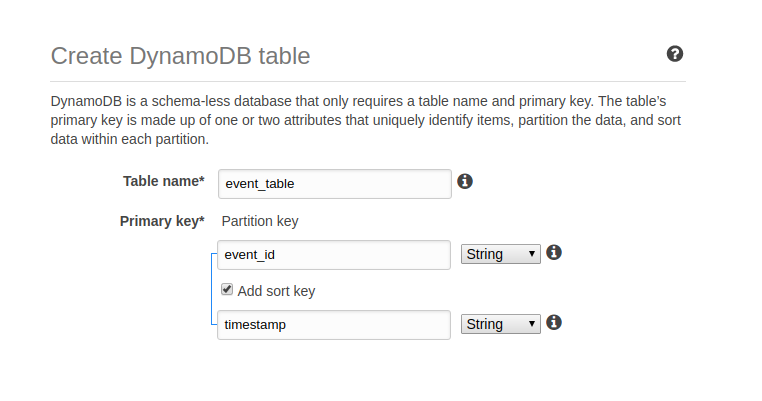
Understanding the primary key and sort key is critical for success with DynamoDB. Here is what you need to know about the fields you must determine upfront with a table:
Primary Key (Partition Key) is a key primarily for scalability. This key is used to distribute your database across partitions. The primary key doesn’t have to be unique.
Amazon really nails it here:
The partition key is used to partition data across hosts for scalability and availability. Choose an attribute which has a wide range of values and is likely to have evenly distributed access patterns. For example CustomerId is good while GameId is bad if most of your traffic relates to a few popular games.
AWS Tool Tip on DynamoDB Table create page. Source: https://console.aws.amazon.com/dynamodb/home?region=us-east-1#create-table:
The Sort Key is a the key that can be used to perform advanced queries on the database. More on using the sort key later on.
Composite Key is the combination of the primary(partition) key and sort key. The sort key and the primary key must always be unique for each record.
Design Considerations for Querying Data
Now that you understand the basics of the DynamoDB keys, let’s review some scenarios in which you will query data since the way you save your data in the DynamoDB determines how you will be able to query it.
The primary(partition) key is always required. To query for that key, you must know the key.
Let’s look at two common types of data you would find in a database. There is time-based data and key-based data.
Examples of time-based data would be blog posts or analytics in which you care when an entry was added to the database. For time-based data, you need to specify a sort key in a format you can query by.
The most obvious way to query time-based data is by the timestamp. Let’s say we have the following data in our database. In this example, event is the primary key and time is the sort key.
[
{
"event": "clicked button",
"time": 1
},
{
"event": "clicked button",
"time": 2
}
]In order to query this data, I could specify the event name like this:
result = event_table.query(
KeyConditionExpression=Key('event').eq('clicked button')
)The result of this would be all the events that matched “clicked button”. Using the sort key, I could also specify a range using the “gt” function:
Note: You must always provide the Primary key. You cannot query only by the sort key.
def get_latest_events():
"""Query latest event."""
result = event_table.query(
ScanIndexForward=True,
KeyConditionExpression=(
Key('event').eq('clicked button') &
Key('timestamp').gt(1)
)
)
return resultResult adding the sort key to the query:
[
{
"event": "clicked button",
"time": 2
}
]This a basic example of using sort. The best practice time series data is to use the date as the primary key. You want the partition key to be unique so that it is easily distributed across the database system.
Dive deeper into querying the database here:
CRUD Examples for DynamoDB and Boto3
Boto3 is the goto SDK for working with Dynamodb in Python. Here are the crud operations you need to know with examples.
Create DynamoDB Table
def create_user_table():
"""Create the user table."""
try:
result = client.create_table(
TableName='user_table',
BillingMode='PAY_PER_REQUEST',
AttributeDefinitions=[
{
'AttributeName': 'char',
'AttributeType': 'S'
},
{
'AttributeName': 'email',
'AttributeType': 'S'
}
],
KeySchema=[
{
'AttributeName': 'email',
'KeyType': 'HASH'
},
{
'AttributeName': 'char',
'KeyType': 'RANGE'
}
]
)
return result
except Exception as e:
return str(e)create_user
Doc:
Create a new user in DynamoDB.
Source:
def create_user(email):
"""Create a new user in DynamoDB."""
result = user_table.put_item(Item={
'email': email,
'char': email[:1],
'human_date': str(datetime.utcnow()),
'created_at': str(int(time.time()))
})
return resultResult:
{
"ResponseMetadata": {
"RequestId": "8R47UH037A0K8H0EGKI98NOJE3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"server": "Server",
"date": "Sun, 18 Aug 2019 21:09:33 GMT",
"content-type": "application/x-amz-json-1.0",
"content-length": "2",
"connection": "keep-alive",
"x-amzn-requestid": "8R47UH037A0K8H0EGKI98NOJE3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"x-amz-crc32": "2745614147"
},
"RetryAttempts": 0
}
}index
Doc:
Select all users from the table.
Source:
def index():
"""Select all users from the table."""
users = user_table.scan()
return usersResult:
{
"Items": [
{
"created_at": "1566162573",
"char": "r",
"email": "richard.be.jamin@gmail.com",
"human_date": "2019-08-18 21:09:33.147595"
}
],
"Count": 1,
"ScannedCount": 1,
"ResponseMetadata": {
"RequestId": "80FUP7E3N3PRUK106AO386PUC3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"server": "Server",
"date": "Sun, 18 Aug 2019 21:09:33 GMT",
"content-type": "application/x-amz-json-1.0",
"content-length": "180",
"connection": "keep-alive",
"x-amzn-requestid": "80FUP7E3N3PRUK106AO386PUC3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"x-amz-crc32": "2972745174"
},
"RetryAttempts": 0
}
}read_user
Doc:
Get a user from the table by email.
Source:
def read_user(email):
"""Get a user from the table by email."""
result = user_table.query(
KeyConditionExpression=Key('email').eq(email)
)
return resultResult:
{
"Items": [
{
"created_at": "1566162573",
"char": "r",
"email": "richard.be.jamin@gmail.com",
"human_date": "2019-08-18 21:09:33.147595"
}
],
"Count": 1,
"ScannedCount": 1,
"ResponseMetadata": {
"RequestId": "UUJ2SSN1ISPL1R85H7KMKIUA1VVV4KQNSO5AEMVJF66Q9ASUAAJG",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"server": "Server",
"date": "Sun, 18 Aug 2019 21:09:33 GMT",
"content-type": "application/x-amz-json-1.0",
"content-length": "180",
"connection": "keep-alive",
"x-amzn-requestid": "UUJ2SSN1ISPL1R85H7KMKIUA1VVV4KQNSO5AEMVJF66Q9ASUAAJG",
"x-amz-crc32": "2972745174"
},
"RetryAttempts": 0
}
}update_user
Doc:
Update user information.
Source:
def update_user(email):
"""Update user information."""
result = user_table.update_item(
Key={
'email': email,
'char': email[:1]
},
ExpressionAttributeValues={
':city': 'Tulsa',
':updated_at': str(time.time())
},
UpdateExpression='SET city = :city, '
'updated_at = :updated_at',
ReturnValues='ALL_NEW',
)
return resultResult:
{
"Attributes": {
"city": "Tulsa",
"updated_at": "1566162573.5953672",
"char": "r",
"created_at": "1566162573",
"email": "richard.be.jamin@gmail.com",
"human_date": "2019-08-18 21:09:33.147595"
},
"ResponseMetadata": {
"RequestId": "TT43NU6801F6LP0B2JVAELFAUNVV4KQNSO5AEMVJF66Q9ASUAAJG",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"server": "Server",
"date": "Sun, 18 Aug 2019 21:09:33 GMT",
"content-type": "application/x-amz-json-1.0",
"content-length": "217",
"connection": "keep-alive",
"x-amzn-requestid": "TT43NU6801F6LP0B2JVAELFAUNVV4KQNSO5AEMVJF66Q9ASUAAJG",
"x-amz-crc32": "2746400021"
},
"RetryAttempts": 0
}
}delete_user
Doc:
Delete user by email.
Source:
def delete_user(email):
"""Delete user by email."""
result = user_table.delete_item(
Key={
'email': email,
'char': email[:1]
}
)
return resultResult:
{
"ResponseMetadata": {
"RequestId": "G9LQ19E924MTFMMJ3OAA4FBOVNVV4KQNSO5AEMVJF66Q9ASUAAJG",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"server": "Server",
"date": "Sun, 18 Aug 2019 21:09:33 GMT",
"content-type": "application/x-amz-json-1.0",
"content-length": "2",
"connection": "keep-alive",
"x-amzn-requestid": "G9LQ19E924MTFMMJ3OAA4FBOVNVV4KQNSO5AEMVJF66Q9ASUAAJG",
"x-amz-crc32": "2745614147"
},
"RetryAttempts": 0
}
}Caveats of Scan
The one caveat of scan is that the amount of data returned is limited to 1mb.
A single Query operation will read up to the maximum number of items set (if using the Limit parameter) or a maximum of 1 MB of data and then apply any filtering to the results using FilterExpression . If LastEvaluatedKey is present in the response, you will need to paginate the result set. For more information, see Paginating the Results in the Amazon DynamoDB Developer Guide .
AWS DynamoDB documentation. Source: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/dynamodb.html#DynamoDB.Client.scan
In order to bypass this limitation, you can wrap the scan in a while loop. Although it is not ideal. the following code does bypass the 1mb limitation.
def scan_all(dynamodb_table):
"""Return all items from a DynamoDB table by passing the table resource."""
results = []
has_items = True
last_key = False
while has_items:
if last_key:
data = dynamodb_table.scan(ExclusiveStartKey=last_key)
else:
data = dynamodb_table.scan()
if 'LastEvaluatedKey' in data:
has_items = True
last_key = data['LastEvaluatedKey']
else:
has_items = False
last_key = False
for item in data['Items']:
results.append(item)
return resultsConclusion
DynamoDB is a great technology to use for an app or website. The benefits of DynamoDB are the same as all serverless technology, the ability to scale without managing servers. There is a learning curve to DynamoDB and some quirks that you need to know to have success using this technology. I hope this was helpful. Thanks for reading!